Time and State in Distributed System
Time in DS
- Each machine in a distributed system has its own clock providing the physical time.
- The distributed system do not have global physical time.
- Time synchronization is essential to know at what time of day a particular event occurred at a particular computer within a system.
Physical Clock
- Each computer contains an electronic device that counts oscillations in a crystal at a definite frequency and store division of count to frequency in a register to provide time. Such device is called physical clock and the time shown is physical time.
- Since, different computers in a distributed system have different crystals that run at different rates, the physical clock gradually get out of synchronization and provide different time values.
- Due to this, it is very difficult to handle and maintain time critical real time systems.
- Consistency of distributed data during any modification is based on time factor.
Synchronization of Physical Clocks
The algorithms for synchronization of physical clocks are as follows:
1. Christian's method
2. Berkeley's method
3. Network time protocol
Cristian’s Method
- It makes use of a time server to get the current time and helps in synchronization of computer externally.
- Upon request, the server process S provides the time according to its clock to the requesting process p.
- This method achieve synchronization only if the round trip times between client and time server are sufficiently short compared to the required accuracy.
Algorithm:
- A process p requests time in a message mr and receives time value t in a message mt. Process p records total round trip time T(round) taken to send request mr and receive reply mt.
- Assuming elapsed time is splitted before and after S placed t in mt, the time estimate to which p should set its clock is t + T(round)/2.
- Assuming min as the earliest point at which S could have placed time mt after p dispatches mr, then:
a) Time by S’s clock when reply arrives is in range [t + min, t + T(round) – min]
b) Width of time range is T(round) – 2 * min
c) Accuracy is +- (T(round) /2 – min)
Discussion:
- If a time server fails, the synchronization is impossible.
- To remove this drawback, time should be provided by a group of synchronized time servers.
Berkeley’s Algorithm
- It is an algorithm for internal synchronization.
- A computer is chosen as a master.
- All other computers are slaves.
- Master periodically polls for the time of slaves and the slaves send back their clock values to master.
- The master estimates local time of each slave by observing the round-trip times.
- Master calculates average of obtained time including its own time.
- While calculating average, it eliminates faulty clocks by choosing a subset of clocks that do not differ from one another by more than a specified amount.
- The master then sends the amount by which each slave should adjust their clock which may be positive or negative.
- If the master fails, one of the slaves can be elected to take the place of master.
Network Time Protocol (NTP)
- It defines an architecture to enable clients, across the Internet to be synchronized accurately to UTC.
- It synchronizes against many time servers.
Design Aims:
- Adjust system clock close to UTC over Internet.
- Handle bad connectivity
- Enable frequent resynchronization
- Security
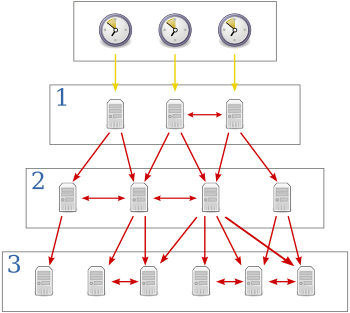
Hierarchical Structure of NTP:
- NTP is provided by a network of servers located across the Internet.
- Primary servers are connected directly to a time server.
- Secondary servers are synchronized with primary servers.
- The logical hierarchy of server connection is called synchronization subnet.
- Each level of synchronization subnet is called stratum.
- Lowest level executes in user's workstation.
- Server with high stratum numbers are liable to have less accurate clocks.
Server synchronization can be done in following ways:
1. Multicast mode:
- Servers periodically multicasts time to other servers in the network.
- Receivers set their clock assuming small delay.
2. Procedure Call mode:
- One server accepts requests from other computers.
- Server replies with its timestamp.
3. Symmetric mode:
- A pair of servers on higher subnet layers exchange messages to improve accuracy of synchronization over time.
Working of NTP
- It calculates offset oj and delay dj as:
oj = T(B) - T(A) = [(T2 - T1) + (T4 - T3)] /2
dj = T(ABA) = [(T4 - T1) - (T3 - T2)]
- The real offset o is :
[oj - dj / 2] <= o <= oj + dj / 2]
Logical Clock
- Logical clock is a virtual clock that records the relative ordering of events in a process.
- It is a monotonically increasing software counter.
- It is realized whenever relative ordering of events is more important than the physical time.
- Physical clocks are not needed to be synchronized.
- The value of logical clock is used to assign time stamps to the events.
Lamport Logical Clock
- The ordering of events is based on two situations:
1. If two events within a same process occurred, they occured in the order in which that process observes.
2. Whenever a message is sent between processes, the event of sending message occurred before the event of receiving the message.
- Lamport generalizes the two conditions to form happened-before relation, denoted by -->
i.e a --> b ; meaning that event a happened before event b
- According to Lamport:
1. If for some process pi: a --> b, then a --> b.
2. For any message m, send(m) --> receive(m)
3. If a, b and c are events such that a-->b and b-->c, then a --> c.
4. If a --> b, event a casually affects event b.
5. If a --> e and e --> a are false, then a and e are concurrent events, which can be written as a || e.
Implementation Rules:
1. Cpi is incremented before each event is issued at process Pi.
CPi := CPi + 1
2. a) When send(m) is a event of process Pi, timestamp tm = CPi(a) is included in m.
b) On receiving message m by Pj, its clock CPj is updated as:
CPj := max [ CPj, tm ]
c) The new value of CPj is used to timestamp event receive(m) by Pj
Problems:
1. Lamport's logical clock impose only partial order on set of events but pairs of distinct events of different processes can have identical time stamp.
2. Total ordering can be enforced by global logical time stamp.
Vector Clock
- Vector clock is a clock that gives ability to decide whether two events are causally related or not by looking at their time stamps.
- A vector clock for a system of N processes is an array of N integers.
- Each process keeps its own vector clock Vi used to time stamp local events.
- The disadvantage is that it takes more amount of storage and message payload proportional to the number of processes.
Rules for clock update
1. Initially Vi[j] = 0 for i, j = 1, 2, 3, .......... N
2. Just before Pi time stamps an event, it sets Vi[i] := Vi[i] + 1
3. Pi includes the value t = Vi in every message it sends.
4. When Pi receives a time stamp t in a message, it sets Vi[j] := max(Vi[j] , ti[j]), for j = 1, 2, 3, .. N
Global State and State Recording
- In a distributed system, global state consists of local state of each process (message sent and message received) and state of each channel (message sent but not received).
- The challenge is to record the global state.
- The problem is due to lack of global clock because of which the local states are recorded at different time for each process.
Consistent Global State
- A global state is consistent if for any received message in the state the corresponding send is also in the state.
- A cut C is said to be consistent, if for each event it contains, it also contains all the events that happened before that event.

Distributed Snapshot Algorithm
Assumptions:
1. Communication is reliable so that every message sent is eventually received exactly once.
2. Channels are unidirectional and provide FIFO ordered message delivery.
3. The graph of processes and channels are strongly connected.
4. Any process may initiate a global snapshot at any time.
Algorithm:
Marker receiving rule for process Pi :
On Pi's receipt of a marker message over channel c:
if (Pi has not yet recorded its state) it:
records its process state;
records state of c as empty set;
turns on recording of messages over incoming channels;
else
Pi records state of c as set of messages received over c;
end if
Marker sending rule for process Pi:
After Pi has recorded its state, for each outgoing channel c:
Pi sends one marker message over c before it sends any other message over c;

Ⓒ Copyright ESign Technology 2019. A Product of ESign Technology. All Rights Reserved.