Searching and Indexing Big Data
Full Text Indexing and Searching
Indexing
- The process of converting text or original data into a format that allows highly efficient cross reference lookup to facilitate rapid searching is known as indexing.
- It is the first step in search application.
- It eliminates the slow sequential scan during searching.
Searching
- Searching is the process of looking up the words in an index to find documents where they appear.
Indexing Process
1. Crawl all the pages of the seedlist and persist them to disk.
2. Extract the file content and persist it to disk.
3. Crawl the seedlist page from the disk.
4. Index the seedlist entries into documents.
5. Write the documents to the index.
6. Repeat until all the seedlist page have been crawled.
Document Search
- Document search is the component of Document Management System that is used to search for documents based on various criteria.
- It also supports text search within the original document.
Indexing with Lucene
Lucene
- Lucene is a high performance and scalable JAVA based information retrieval library that adds indexing and searching capabilities to the application.
- It is the core of any search application that provides all the functionality required by a search application except for the user interaction.
- It is an open source library.
- It is competitive in engine performance, relevancy and code maintenance.
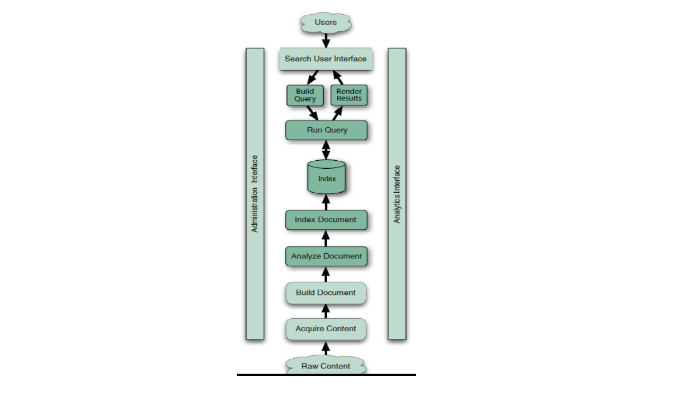
Components of Search Application
1. Acquire Raw Content
- It is the first process of any search application.
- It helps to collect the target contents on which search application needs to be performed.
- All these contents are in raw format.
2. Build Document
- Document in Lucene is a collection of fields, which is easy to understand and interpret.
- The collected raw contents are built into documents so that the search application can easily interpret it.
- It is the process of converting raw contents into application understandable format.
3. Analyze Document
- The document is analyzed to find out which part of the document is the candidate for indexing.
4. Indexing Document
- Indexing is done for a document.
- It helps in retrieving document based on keys instead of entire document content.
- It creates index as the output.
- All the indexes are stored in the database.
5. User Search Interface
- The search application can make queries once the index are stored in database.
- It is the interface provided to the user to facilitate user to make query.
6. Build Query
- Once a user make request to search a text, the application prepare a Query object using that text.
- This object is used to inquire index database.
7. Search Query
- The index database is then checked using the query object to obtain the relevant details or contents.
8. Render Request
- After receiving the result from the search query, the application should show the results to the user.
- The user interface is used for this process.
-
Lucene Indexing Process
1. Document Analyzer
2. Index Writer
3. Index Store
Analyzers
1. White Space Analyzer
- It splits the tokens based on white spaces.
2. Simple Analyzer
- It splits the tokens based on non-letters and then lowercase it.
3. Stop Analyzer
- It splits the tokens based on non-letters and then lowercase it and also removes the stop words.
4. Standard Analyzer
- It splits the tokens based on certain token types like name, e-mail address and so on, lower case it, removes the stop words, common words, punctuation and so on.
For example : Consider the text:
"The quick brown fox jumped over the lazy dog"
1. [The] [quick] [brown] [fox] [jumped] [over] [the] [lazy] [dog]
2. [the] [quick] [brown] [fox] [jumped] [over] [the] [lazy] [dog]
3. [quick] [brown] [fox] [jumped] [over] [lazy] [dog]
4. [quick] [brown] [fox] [jumped] [over] [lazy] [dog]
Distributed Searching with Elastic Search
Elastic Search
- Elastic search is the highly scalable open source full text search and analytic engine based on Lucene.
- It provides a distributed, multitenant-capable full-text search engine with HTTP web interface and schema free JSON documents.
- It is developed in JAVA.
- It is used to search all kinds of documents.
- It achieves fast search response due to index searching.
Benefits of Elastic Search
- It is open source.
- It is easy to deploy.
- It can be scaled vertically as well as horizontally.
- It provides easy to use API and supports various programming and scripting languages.
- It has active community and well formatted documentation.
Write the equivalent Elasticsearch query to find the unique employee_id and corresponding salary.
GET /_search
{
"size" : 0,
"aggs" : {
"distinct_employee" : {
"terms" : {
"script" : "[doc['employee.employee_id'].value, doc['employee.salary'].value]",
"size" : 1000
}
}
}
}

Ⓒ Copyright ESign Technology 2019. A Product of ESign Technology. All Rights Reserved.