Map-Reduce Framework
Functional Programming
- Functional programming is the declarative programming paradigm that treats computation as the evaluation of mathematical functions.
- It means programming is done with expressions or declarations rather than statements.
- The output value of a function only depends on the arguments passed to that function. It implies that passing the same argument value yields the same output each time the function is executed.
Benefits of Functional Language
1. It has no side effects.
2. The function does not rely upon any external states, so it is easier to maintain.
3. It does not have any assignment statements.
4. It does not make use of variables, so there is no change in state.
5. It has simple and uniform syntax.
6. It can be implemented via interpreters rather than compiler.
7. It is mathematically easier to handle.
8. The programs can be made concurrent automatically.
9. The overhead in computation such as loops are not present, making the execution faster.
10. It encourages safe way of programming.
11. It is easier to refactor and changes in design are easier to implement.
12. It is easy to test and debug in isolation.
Example of Functional program in Python
The given example shows the implementation of functional programming in Python to print a list with first 10 fibonacci number.
fibonacci = (lambda n, first = 0, second = 1:
[ ] if n == 0 else
[first] + fibonacci(n-1, second, first + second) )
print (fibonacci(10))
Functional programming Vs. Imperative programming
1. In imperative programming, the programmer focuses on how to perform task and how to track changes. In functional programming, the programmer focuses on what information is desired and what transformations are required.
2. State changes in imperative programming. State change do not exist in functional programming.
3. Order of execution is important in imperative programming but not important in functional programming.
4. Flow control is managed using loops, conditions in imperative programming while using function call and recursion in functional programming.
5.
Map Reduce Fundamentals
Map Reduce
- MapReduce is a programming model used as an implementational tool for processing and generating big data sets using a parallel and distributed algorithms in a cluster.
- It generally uses split-apply-combine strategy for data analysis.
- It uses map and reduce functions commonly used in functional programming.
Basic Components of Map Reduce
- MapReduce is composed of two components. They are Mapper and Reducer.
- Mapper is the component that execute map() function. The real input to the system is the input for the mapper. The map() function when executed, the given input is converted to a key/value pair to generate intermediate key/value pairs.
- Reducer is the component that execute reduce() function. The intermediate key/value pair generated from mapper is the input to reduce() function. It merge all the intermediate values associated to the same key.
Usage of MapReduce
1. Distributed sort
2. Web link-graph reversal
3. Web access log stats
4. Inverted index construction
5. Document clustering
6. Machine learning
7. Statistical machine translation
Data Flow (Architecture)
Assumptions
Let us consider that:
M represents number of map task.
R represents number of reduce task.
W represents number of machine.
Data Distribution
- The input data files are distributed into M number of pieces on the distributed file system.
- The intermediate output of map function are stored in the local disk of each machine as a intermediate file.
- The final output file is written to distributed file system.
Execution Overview
1. Map
- It reads the contents of corresponding input partition.
- It performs user defined map computation to create intermediate pairs.
- It periodically writes the output pairs to the local disk.
2. Reduce / Fold
- It iterates over the ordered intermediate data obtained as the output of map function.
- When each unique key is encountered, the values are passed to the user's reduce function.
- The output of reduce function is written to the output file on global file system.
Distributed Execution
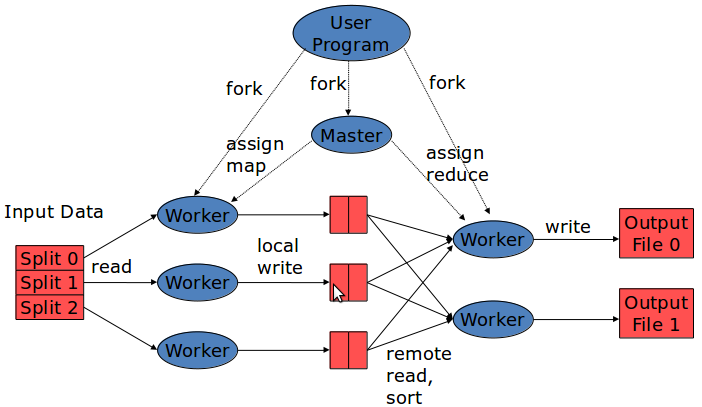
- The MapReduce library in the user program splits the input files into M pieces. It then starts up many copies of the program on the cluster of machines.
- One of the copies acts as a master and others as workers. There are M map tasks and R reduce tasks. The master selects the idle workers and assigns each one either a map task or a reduce task.
- A worker who is assigned with the map task reads the content of the input split. The user defined map function generates key/value pairs from the input split. The intermediate key/value pair produced are stored in the local disk partitioned into R regions by the partitioning function.
- The locations of the pairs in the local disks are passed to the master, which is responsible to forward to the reduce worker.
- When the reduce worker get notified from the master about the locations, it uses remote procedure calls to read the data from the local disks of map workers. After reading all the intermediate data, it sorts them by the intermediate keys.
- The reduce worker iterates over the sorted intermediate data and for each unique key it encountered, it passes the key and the corresponding set of intermediate values to the user's Reduce function. The output of the Reduce function is appended to a final output file for this reduce partition.
- When all map and reduce tasks are completed, the master wakes up the user program.
Combiner Function
- Combiner function is the function that is responsible to accept the output of the Map function, summarize the output records with the same key and pass each key data to one of the Reduce function.
- It helps to segregate data into multiple groups for Reduce phase.
- It helps in easier processing of the Reduce task.
- It produces output as key-value collection pairs.
Real World Problems
Map Reduce Program to find word frequency
Implementation in JAVA
public class WordCount {
public static class WordMapper extends Mapper
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class CountReducer extends Reducer
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordMapper.class);
job.setCombinerClass(CountReducer.class);
job.setReducerClass(CountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Implementation in Python
import sys
class mapper(object):
def __init__(self, text):
super(mapper, self).__init__()
self.text = text
def map(self):
self.words = self.text.split()
self.map_output = []
for word in self.words:
self.map_output.append({word : 1})
class reducer(object):
def __init__(self, map_list):
super(reducer, self).__init__()
self.map_list = map_list
def reduce(self):
self.reduce_output = {}
for length in range(0,len(self.map_list)):
current_pair = self.map_list[length]
current_word = current_pair.keys()
current_count = 0
for i in self.map_list:
key = i.keys()
if current_word == key:
current_count = current_count + 1
self.reduce_output[current_word[0]] = current_count
text = 'Ram is a good boy He is one of the best boy in the class'
mapper_obj = mapper(text)
mapper_obj.map()
map_output = mapper_obj.map_output
reducer_obj = reducer(map_output)
reducer_obj.reduce()
for frequency in reducer_obj.reduce_output.keys():
print '%s = %s' %(frequency, reducer_obj.reduce_output[frequency])
Fault Tolerance in Map Reduce
Machine Failure
- The master pings workers regularly to detect the failures.
- If no response is returned by the worker, the worker is considered to be faulty.
- When the map worker failure is encountered, the map task to that worker is reset to idle and resheduled to another map worker. The reduce workers are notified about this resheduling.
- When the reduce worker failure is encountered, the task that are not completed i.e in progress task are reset to idle and resheduled to another reduce worker.
- In case of failure of the master, the complete MapReduce task is aborted and is notified to the client.

Ⓒ Copyright ESign Technology 2019. A Product of ESign Technology. All Rights Reserved.