Record Organization
- Database is stored in a collection of files
- Each file is a sequence of records.
- A record is a sequence of fields.
Fixed length records
- The record size is fixed and each file has only one type of records.
- For different relations , files are different.
- It is easy to implement ,
- Store record I starting from byte n*(i-1) where n is record size.
- It is difficult to delete a record from the structure
- Sometimes record may cross the boundaries , so two block access is required.
- For deletion:
1. Move records it1 ….. n to I,……. N-1 but more access to move
2. Link all free records on free list.
3. Store address of deleted record in file header
Variable length records
- The variable length record occurs due to :
- Storage of multiple record types in a single file.
- Record types allowing variable lengths for fields
- Record types allowing repeating fields,
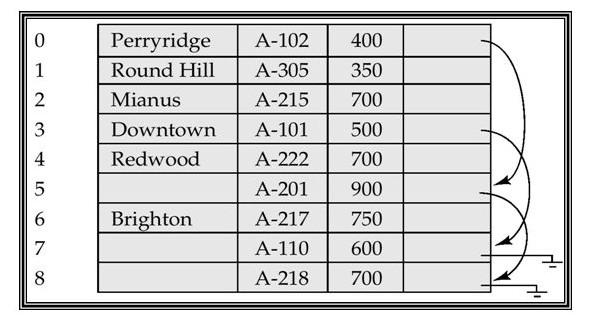
1. Byte-string representation
- A special end of record (1) symbol is attached at the end of record.
- It is difficult to reuse space occupied by deleted records
- The records cannot grow
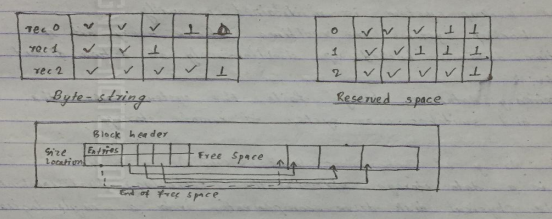
2. slotted page structure
- It is modification of byte spring representation
- Slotted page header contains number of records , end of free space,location and size of each record.
- Records can be moved to keep them contiguous but header must be updated.
3. fixed length representation
- A reserved space is used for fixed length records of known maximum length and unused space are filled with a null.
- A list representation uses fixed length records of a known maximum length.
Organization of records in files.
1) Heap organization :
a. A record can be placed in any free space.
2) Hash organization
a. A result of hash function specifies in which block of the file the record should be placed
3) Sequential organization
a. The records are stored sequentially , the records are ordered by a search key . for fast retrievel, records are linked together by pointer.
Disks and Storage
- Storage devices are arranged hierarchically as follows:
cache
main memory
flash memory
magnetic disk
optical disk
magnetic tape
Remote Backup System
- It is the backup of data or copy of a database stored at a remote location from where it can be restored in case of destruction of database in primary location.
- It can be offline or online
- Offline backup system is maintained manually,
- Online backup systems are realtime where every bit of real time data is backed up simultaneously at two distant places.
- As primary database storage fails, the system senses the failure and switches user system to remote storage.
Redundant array of independent disks (RAID)
- Raid is a data storage virtualization technology that combines multiple physical disk drive components into a single logical unit for the purpose of data redundancy and performance improvement
- Data is distributed across drives in several ways called RAID levels.
- Each level provides different balance among reliability availability performance and capacity
RAID Levels
1) RAID 0
a. It consists of stripping without mirroring or parity
b. It’s capacity is the sum of capacities of disks in a set
c. It can not handle disk failure.
d. Stripping distributes file contents equally among all disk sin a set that enables concurrent operations
2) RAID 1
a. it consists of data mirroring.
b. Data is written identically to more drives
c. Any operation can be serviced by any drive in the set.
d. The one that access data first services the request.
e. Write performance is very slow
3) RAID 2
a. It consists bit level mapping with harming code parity
b. Each sequential bit is an different drive
4) RAID 3
a. It consists of byte level stripping with dedicated parity
5) RAID 4
a. It consists of block level stripping with dedicated parity
b. It supports i/o parallelism/
c. i/operation does not need to spread across all drives.
6) RAID 5
a. it consists of block level stripping with distributed parity
b. if one drive fails, subsequent read can be calculated from distributed parity
c. it is susceptible to system failures.
7) RAID 6
a. Block level stripping with double distributed parity
b. Provides fault tolerance upto two foiled drives
Static and Dynamic Hashing ; Indexing
Indexing and hashing
- Indexing is a mechanism to speed up access to desired data.
- A index file consists of records with search key and pointer.
- Search key is the attribute used to lookup records in a file.
- The record evaluation metrices are :
1. Access type
2. Access time
3. Insertion time
4. Deletion time
5. Space overhead
Ordered index
- The index entries are sorted on the search key value.
- Index is of two types:
1. Primary Index
2. Secondary Index
Primary index (clustering index)
- The index whose search key specifies sequential order of file
- Search key is usually a primary key.
1. Dense index
- Index record appears for every search key value in the file
- Index record contains search key and pointer to the first data record with that value.
- Other records with that value are stored sequentially in a file.
2. Sparse index
- Index records appear for some search key value only
- Applicable when records are sequentially ordered on search key
- To locate a record with search key value k
- Find index record with la
- It requires less space and less maintainance overhead.
- It is slower.
3. Multilevel index
- Treat primary index kept on disk as a sequential file and construct a outer sparse index on it,
- All level of indices must be updated on each operation from the file.
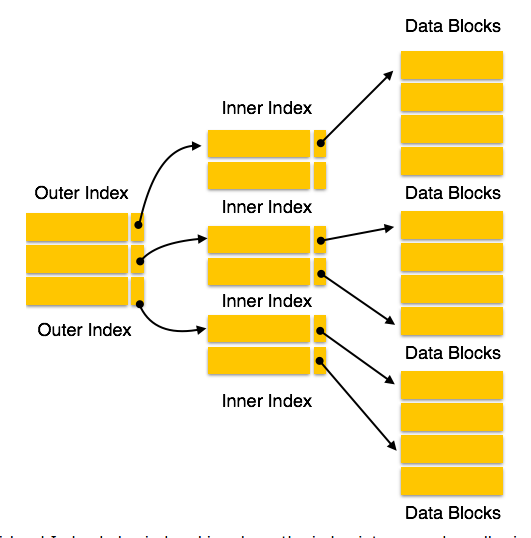
Secondary index
- The index whose search key specifies order different from sequential order of the file.
- It must contains pointers of all records
- Index record points to a bucket that contains pointers to all actual records with that search key values.
- It must be dense.
Hashing
- Bucket is a unit of storage containing one or more records
- In hashing,we obtain the bucket directly from search key value using hash functions
- Hash function h is a function from which the set of all search key values k to the set of all bucket address B
- It can be used for access , insertion as well as deletion.
- Entire bucket has to be searched sequentially to locate a record
Types of hash functions
- A hash function is worst if its maps all search key values to the same bucket
- A hash function is uniform if it maps same number of search key values to each bucket.
- A hash function is random if it maps equal number of records to each bucket.
Bucket overflow
- Bucket overflow is the condition resulted due to insufficient buckets and skew.
- To remove bucket overflow nB > nR/fR
- Skew occurs due to non uniform distributions of key values by a hash functions and multiple records with same search key value.
- Overflow buckets are used to handle it.
- Closed hashing is the chaining of overflow buckets with the buckets in linked list.
Hash index
- A index structure that organizes search keys with their associated record pointers into a hash file structures is called hash index,
- It is a secondary index.
Static hashing
- A hash function h maps search key values to a fixed set of bucket address B
- The main problem arises when databases grow or shrink with time.
- If initial no of buckets is too small, due to more overflows as file grows , performance is reduced.
- If file shrinks or if space is allocated for growth , it will waste space.
- Periodic reorganization with new hash function can solve it but is expensive.
Dynamic hashing / extendable hashing
- The set of keys can be varied and address space is mapped dynamically
- Growth and shrink of database do not affect the organization.
- Hash function can be modified dynamically.
- Extendable hashing is a form of dynamic hashing.
- Keys stored in bucket and each bucket can hold fixed item.
- Index is an extendible table.
- H(x) hashes a key value n to a bit map.
- Extra indirection level to find desired record
- Bucket address table itself may become big.
- Changing size of bucket address table is expensive
- Minimal space overhead.
- Once a bucket is filled, it is splitted.
- No reorganization is required when data are added to or deleted from the file.
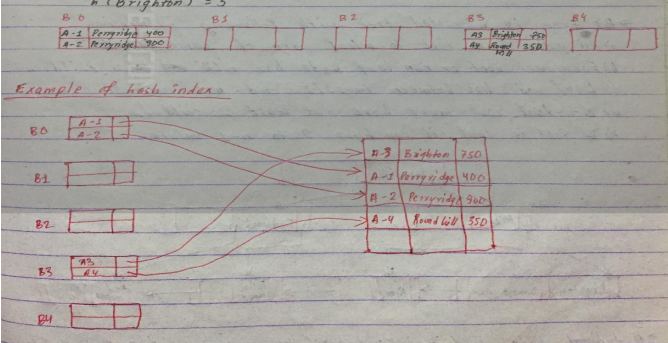
Example of hashing
Consider there are 5 buckets , binary of ith character is integer I and hash function returns sum of binary of characters module 5 then
H(Perryridge) = 0
H(Round hill) = 3
H(brighton) = 3
Hence , here the data is fed into particular algorithm and hash is created.
Hashing is better to retrieve records with specified value of key
Ordered index is better for range queries.
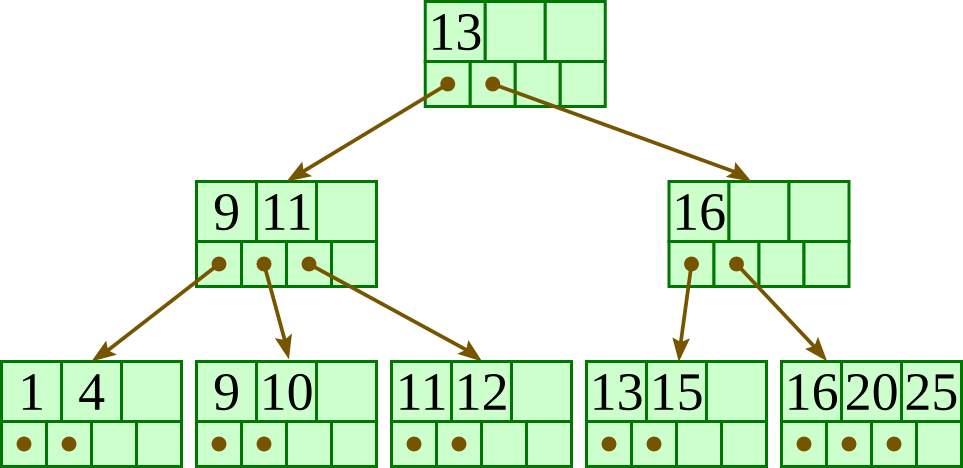
B+ Tree Index
- It is alternative to index sequential files.
Advantages
- Automatic reorganization of insertion and deletion
- Perform is independent of entire file reorganization
Disadvantages
- As file grows , overflow blocks are created.
- Periodic reorganizations of entire file is required
- Space overhead
Properties
B+ tree is a rooted tree with following properties.
1. All paths from root to leaf are of same length.
2. Each non root or non leaf node has n/2 to n children
3. Leaf node has between n-1 /2 and n-1 values
4. Non-leaf root must have 2 children
5. If root is leaf , it can have 0 to n-1 values.
6. A typical node contains ki (search key value ) and Pi (pointer to children for non-leaf nodes or pointer to records of records for leap nodes)
7. K1 > k2 < k3……

Ⓒ Copyright ESign Technology 2019. A Product of ESign Technology. All Rights Reserved.