Fault Tolerance
Introduction to Fault Tolerance
- Fault means defects within hardware or software unit.
- Error means deviation from accuracy.
- Failure is the condition occured when error results system to function incorrectly.
- Fault tolerance means ability to provide services despite of faults occur in some node of the system.
- A system is said to be k-fault tolerant if it is able to function properly even if k nodes of the system suffer from concurrent failures.
Dependabililty requirements of fault tolerant system
1. Availability (system should be available for use at any given time)
2. Reliability (system should run continuously without failure)
3. Safety (temporary failures should not result in a catastrophe)
4. Maintainability (a failed system should be easy to repair)
5. Security (avoidance or tolerance of deliberate attacks to the system)
Types of Faults
1. Node fault
2. Program fault
3. Communication fault
4. Timing fault
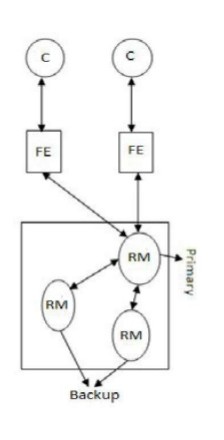
Primary backup replication or Passive replication
- At any point of time, there is a single primary replica manager and one or more secondary replica managers or backups.
- The front end of the system is able to communicate only with the primary replica manager to obtain the service.
- The primary replica manager executes the operations and sends updated data to the backups.
Event Sequence:
1. Request : The FE issues request to the primary RM with unique identifier.
2. Coordination : Primary RM takes the request in the order in which it receives it and re sends the response if already executed.
3. Execution : The primary RM executes request and stores response.
4. Agreement : If request is an update, primary RM sends updated state, response and unique identifier to all the backups. The backups send an acknowledgement.
5. Response : The primary RM responds to front end.
Advantages:
1. It is simple and easy to implement.
2. It can be implemented even if primary RM behaves non-deterministically.
Disadvantages:
1. It provides high overhead.
2. If primary RM fails, more latency is incurred as new view is formed.
3. It can not tolerate byzantine failures.
Active Replication
- The replica managers are state machines that play equivalent roles.
- FE multicast requests to the group of RM and all of them process the requests independently but identically and reply.
- If any RM crashes, others RM can responds. So, there is no degradation on performance.
- It can tolerate byzantine failures.
Event Sequence:
1. Request : The FE attaches a unique identifier to the request and multicast it to the group of RM. It does not issue the next request until it has received a response.
2. Coordination : The group communication system delivers the request to every correct RM in the same order.
3. Execution : Every replica manager executes the request.
4. Agreement : No agreement phase is needed.
5. Response : Each replica manager sends its response to the FE. The no of replies that the FE collects depends upon failure assumptions.
Advantages:
1. It can tolerate byzantine failure.
2. If any RM fails, it does not affect system performance.
Disadvantages:
- RM must be deterministic.
- Atomic broadcast protocol must be used.
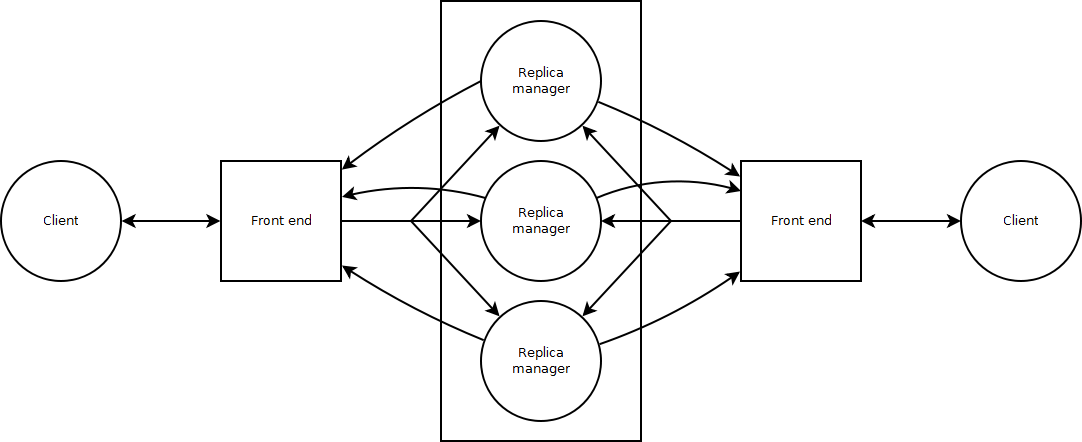
Process Resilience
- Process resilience is a mechanism to protect against faulty processes by replicating and distributing computations in a group.
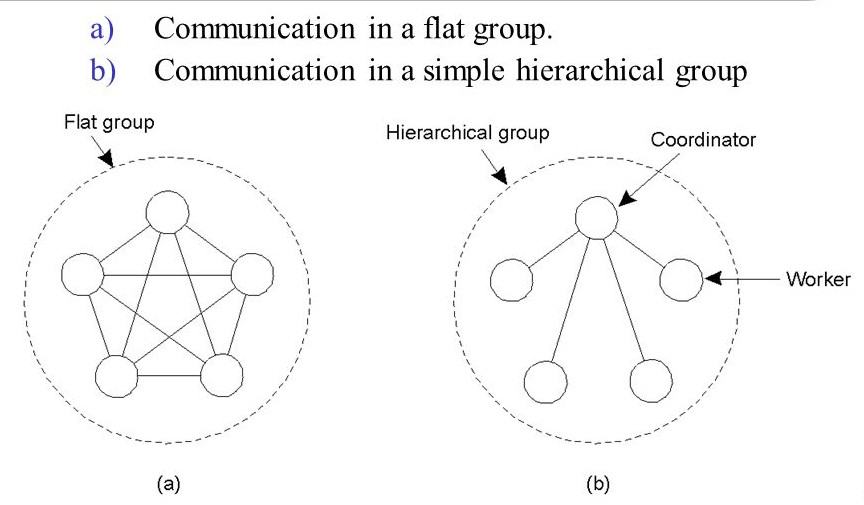
Flat and Hierarchical Groups
- In flat groups, all the processes within a group have equal roles.
- Control is completely distributed to all the processes.
- It is good for fault tolerance as information is exchanged immediately.
- It impose more overhead.
- It is difficult to implement.
- In hierarchical group, all the communications are handled by a single process designated as coordinator.
- It is not completely fault tolerant and scalable.
- It is easy to implement.
Byzantine Generals Problem
- In this case, the faulty node can also generate arbitrary data, pretending to be a correct one, but making fault tolerant difficult.
Problem:
- Can N generals reach agreement with a perfect channel if M out of N may be traitors?
For N = 4 and M = 1:
- The vector assembled by each general:
1 Got (1, 2, x, 4)
2 Got (1, 2, y, 4)
3 Got (1, 2, 3, 4)
4 Got (1, 2, z, 4)
- Tje vector that each general receives:
1 Got :
(1, 2, y, 4)
(a, b, c, d)
(1, 2, z, 4)
2 Got:
(1, 2, x, 4)
(e, f, g, h)
(1, 2, z, 4)
4 Got:
(1, 2, x, 4)
(1, 2, y, 4)
(i, j, k, l)
Conclusion:
- With m faulty processes, agreement is possible only if 2m + 1 processes function correctly.
Reliable Client Server Communication
Reliable Communication
- During communication between client and server, following may go wrong:
1. Client unable to locate server
2. Client request is lost
3. Server crashes
4. Server response is lost
5. Client crashes
- The solutions are:
1. Report back to client
2. Resend the message
3. Use of RPC semantics
4. Operations should be idempotent.
5. Kill the orphan computation
Reliable Multicasting
Problems:
- Message lost
- Acknowledgement lost
- Receiver suppresses their feedback
Solutions:
- Atomic multicast guarantees all process received message or none at all.
Distributed Commit
- It deals with methods to ensure that either all processes commit to the final result or none of them do.
Two Phase Commit
Model:
- The client who initiated computation acts as coordinator.
- Processes required to commit act as participant.
Phases:
1a - Coordinator sends VOTE_REQUEST to participants
1b - When participant receives VOTE_REQUEST, it reply with YES or NO. If it sends NO, it aborts its local computations.
2a - Coordinator collects all votes. If all are YES, it sends COMMIT to all participants. Otherwise, it sends ABORT.
2b - Each participants waits for COMMIT or ABORT and handles accordingly.
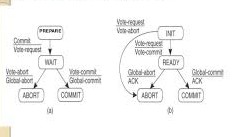
Participant Failure:
1. Initial state = Make transition to ABORT
2. Ready state = Contact another participants
3. Abort state = Make transition to ABORT
4. Commit state = Make transition to COMMIT
Implementation:
1. Coordinator
while START _2PC to local log;
multicast VOTE_REQUEST to all participants;
while not all votes have been collected{
wait for any incoming vote;
if timeout{
while GLOBAL_ABORT to local log;
multicast GLOBAL_ABORT to all participants;
exit;
}
record vote;
}
if all participants sent VOTE_COMMIT and coordinator votes COMMIT{
write GLOBAL_COMMIT to local log;
multicast GLOBAL_COMMIT to all participants;
}
else{
write GLOBAL_ABORT to local log;
multicast GLOBAL_ABORT to all participants;
}
2. Participants:
write INIT to local log;
wait for VOTE_REQUEST from coordinator;
if timeout{
write VOTE_ABORT to local log;
exit;
}
if participant votes COMMIT{
write VOTE_COMMIT to local log;
send VOTE_COMMIT to coordinator;
wait for DECISION from coordinator;
if timeout{
multicast DECISION_REQUEST to other participants;
wait until DECISION is received;
write DECISION to local log;
}
if DECISION == GLOBAL_COMMIT
write GLOBAL_COMMIT to local log;
else if DECISION == GLOBAL_ABORT
write GLOBAL_ABORT to local log;
}
else{
write VOTE_ABORT to local log;
send VOTE_ABORT to coordinator;
}
3. Handling Decision Requests:
/* Executed in separate thread */
while true{
wait until any incoming DECISION_REQUEST is received;
read most recently recorded STATE from local log;
if STATE == GLOBAL_COMMIT
send GLOBAL_COMMIT;
else if STATE == INIT or STATE == GLOBAL_ABORT
send GLOBAL_ABORT;
else
skip;
}
Distributed Recovery
- It is the mechanism to handle failures.
- It helps to recover correct state of the system after failure.
Independent Checkpointing
- Each process periodically checkpoints independent of other processes.
- Upon failure, locate a consistent cut backward.
- It needs to rollback until consistent cut is found.
Coordinated Checkpointing
- The state of each process in the system is periodically saved on stable storage.
- If failure occurs, it rollbacks to previous error free state recorded by the checkpoints of all the processes.
Message Logging
- Combining checkpoint and message logs becomes cheap.

Ⓒ Copyright ESign Technology 2019. A Product of ESign Technology. All Rights Reserved.