Case Study : Hadoop
Introduction to Hadoop Environment
What is Hadoop?
- The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.
- It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
- Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
- It makes use of MapReduce programming model to process data sets.
Why to use Hadoop?
- It facilitates processing of huge data sets easily on large clusters of computers.
- It provides efficient, reliable and easy to use common infrastructure.
- It supports processing of data stored in each node, without necessity of moving data for initial processing.
- It does not rely up on hardware to provide fault tolerant and high availability.
- Servers can be added or removed dynamically without interrupting the operation of the system.
- It is open source, so is available freely.
- It is compatible on almost all the platforms.
Data Flow in Hadoop
Hadoop Master/Slave Architecture
- A basic master and slave architecture of Hadoop is shown in given figure:
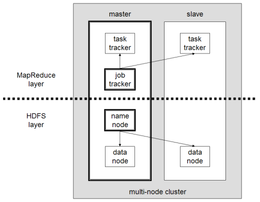
- The above architecture of Hadoop depicts four daemons:
1. NameNode
2. DataNode
3. Job Tracker
4. Task Tracker
Name Node
- The name node is the master of HDFS that helps to direct the data node daemons of slaves to perform the low level I/O tasks.
- It is responsible to keep track of how the files are broken into file blocks, which nodes store those blocks and overall performance of the distributed file system.
- It is memory and I/O intensive. It means that the name node functionality mainly performs memory and I/O tasks.
- It has a single point of failure.
Data Node
- The data node is contained by all the slave nodes of a cluster.
- This daemon is used to perform work of the distributed file system such as read and write HDFS blocks to actual files on local disk.
- Job communicates directly with data node daemon to process the local files corresponding to that block.
- Data replication can be initiated by communication of data nodes.
- It is responsible to report back to name node about the local changes.
Job Tracker
- Job tracker is the mediator between the application and Hadoop.
- It is the master of MapReduce layer of Hadoop.
- It determines the execution plan by determining which files to process, assigns nodes to different tasks and monitors all the running tasks.
- If task on any node fails, job tracker is responsible to re launch the job on another node of the cluster.
- It is responsible for overall work of MapReduce job.
Task Tracker
- Task tracker are present in the MapReduce layer of each nodes.
- It manages the execution of individual MapReduce task on each slave nodes.
- It performs the individual task assigned by the Job tracker.
- If the task tracker fails to execute the assigned job, the job is resheduled by the job tracker.
- A task tracker on each slave node spawns a separate JVM process to prevent itself from failing if the running job crashes its JVM.
Hadoop Ecosystem
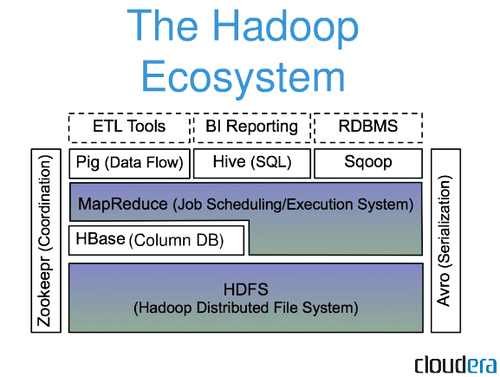
- The Hadoop ecosystem is shown in given figure:
- The Hadoop ecosystem consists of following components:
1. Hadoop Common
2. Hadoop Distributed File System (HDFS)
3. YARN
4. Hadoop MapReduce
- Pig is a platform for analyzing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs.
- Sqoop is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases.
Hadoop Common
- It consists of the common utilities that support other Hadoop modules.
- It is also known as Hadoop core.
- It provides file system and operating system level abstractions.
- It contains Java archive files and scripts needed to start Hadoop.
Hadoop Distributed File System (HDFS)
- It is a file system written in JAVA based on Google's GFS.
- It is a distributed, scalable and portable file system used by Hadoop.
- It is responsible to store data in the cluster.
- It provides redundant storage for huge data sets.
- The data files are split into blocks and are distributed across the nodes in the cluster.
- The details of which blocks forms a file and where they are stored is tracked by the name node.
- The default replication of data in HDFS is 3 fold.
- When a client wants to retrieve data, it communicates with name node to determine the blocks and node storing them; and then the client directly communicates with the data node to read the data.
Yet Another Resource Negotiator (YARN)
- It provides the solution to the scalability problems of classical MapReduce.
- It is a framework for job scheduling and cluster resource management.
- It enables Hadoop to support more varied processing approach and a broader array of applications.
Map Reduce
- It is a method of distributing computations across multiple nodes.
- Each node processes the data that is stored at that node.
Query Language for Hadoop
Hive
- Hive is the query language used by Hadoop.
- It is used to query and manage large data sets of a Hadoop cluster using an SQL like language called HiveQL.
GFS and HDFS
1. File Structure:
- In GFS:
Divided into 64 MB chunks
Chunks identified by 64-bit handle
Chunks replicated (default 3 replicas)
Chunks divided into 64KB blocks
Each block has 32 bit checksum
- In HDFS:
Divided into 128 MB blocks
Name node holds block replica as 2 files (one for data and other for checksum)
2. Architecture Comparison
- In GFS, leases at primary default to 60 seconds. In HDFS, no leases (client decides where to write.)
- The read and write process by client is similar in both GFS and HDFS:
Read Operation: ----------------------------- 1. Client sends request to master 2. Caches lists of replicas 3. Locations provided for limited time
Write Operation:
------------------------------
1. Client obtains replica locations and identify primary replica
2. Client pushes data to replica
3. Client issues update request to primary replica
4. Primary replica forwards write request.
5. Primary receives replies from replicas
6. Primary replica replies to the client
3. Replica Management:
- No more than one replica on one node and no more than two replica's on same rack.
- For reliability and availability, replica's are stored in different nodes present at different racks.
Q) For a Hadoop cluster with 128MB block size, how many mappers will Hadoop infrastructure form while performing mapper functions on 1 GB of data?
Determining the number of mapper for Hadoop
---------------------------------------------------
1. If the file is splittable:
- Calculate total size of input file
- No of mapper = Total input file size / Block size (Split size)
2. If the file is not splittable:
- No of mapper = No of input files
- If the file size is too huge, it becomes bottle neck to the performance of MapReduce.
Solution to numerical problem:
-----------------------------------
1. Assuming the file to be splittable:
No of mappers = 1024 / 128 = 8
2. Assuming the file to be not splittable and data is contained in single file:
No of mappers = 1
Hadoop and Amazon Cloud
- Amazon cloud provides an interface to create and manage fully configured, elastic clusters of instances running Hadoop and other applications in the Hadoop ecosystem.
- Amazon EMR securely and reliably handles a broad set of big data use cases, including log analysis, web indexing, data transformations (ETL), machine learning, financial analysis, scientific simulation, and bioinformatics.
- It uses Amazon EMR to easily install and configure tools such as Hive, Pig, Hbase and many other tools on the personal cluster.
- In the Hadoop project, Amazon EMR programmatically installs and configures applications including Hadoop mapreduce, YARN and HDFS, across the nodes in the cluster.
- By using EMR file system on Amazon cluster, one can leverage Anazon S3 as the data layer for Hadoop.
- By storing data on Amazon S3, one can decouple compute layer from storage layer, allowing one to size the Amazon EMR cluster for the amount of CPU and memory required for the workloads instead of having extra nodes in the cluster to maximize on-cluster storage.
- EMR file system is customized for Hadoop to directly read and write in parallel to Amazon S3 performance.
- Hadoop in Amazon EMR can be used as an elastic query layer.
Advantages of Hadoop on Amazon EMR
1. Increased speed and agility
- One can initialize a new Hadoop cluster dynamically and quickly, or add servers to the existing Amazon cluster.
- It reduces time taken for the resources to be available to the users.
- Using Hadoop on Amazon AWS lowers cost and time it take to allocate resources.
2. Reduced administrative complexity
- Amazon EMR automatically addresses the Hadoop infrastructure requirements, that reduce the complexity to administration.
3. Integration to other cloud services
- The Hadoop environment in Amazon cloud can be integrated with other cloud services like Amazon S3, Amazon DynamoDB and so on easily.
4. Flexible capacity
- With Amazon EMR, one can create clusters with the required capacity within minutes and use auto scaling to dynamically scale out and scale in nodes.

Ⓒ Copyright ESign Technology 2019. A Product of ESign Technology. All Rights Reserved.